Global Tensor¶
全局视角与物理视角的映射¶
创建 Global Tensor¶
要在有2张 GPU 显卡的主机上交互式体验 global tensor,可以用以下方式在2个控制台分别启动 python。
Note
分别 点击 以下 Terminal 0 或 Terminal 1 标签,查看2个控制台的命令/代码
export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=0 LOCAL_RANK=0
python3
export MASTER_ADDR=127.0.0.1 MASTER_PORT=17789 WORLD_SIZE=2 RANK=1 LOCAL_RANK=1
python3
以上的环境变量的设置是做分布式的配置,详细解释及借助工具启动分布式,请参考文末的 扩展阅读
直接创建 global tensor¶
在两个控制台,分别导入 oneflow,并创建 x。
其中 flow.placement("cuda", [0,1]) 指定了 global tensor 在集群的范围。
"cuda"表示在 GPU 设备上。placement的第二个参数是一个list,集群中的设备会被自动编号,通过数字指定使用哪些设备。[0,1]表示 global tensor 使用第 0、1 张显卡上。
import oneflow as flow
placement = flow.placement("cuda", [0,1])
sbp = flow.sbp.split(0)
x = flow.randn(4,5,placement=placement, sbp=sbp)
x.shape
import oneflow as flow
placement = flow.placement("cuda", [0,1])
sbp = flow.sbp.split(0)
x = flow.randn(4,5,placement=placement, sbp=sbp)
x.shape
输出:
oneflow.Size([4, 5])
oneflow.Size([4, 5])
由 global tensor 得到 local tensor¶
通过 to_local 方法可以查看物理设备上的 local tensor:
x.to_local()
tensor([[ 2.9186e-01, -3.9442e-01, 4.7072e-04, -3.2216e-01, 1.7788e-01],
[-4.5284e-01, 1.2361e-01, -3.5962e-01, 2.6651e-01, 1.2951e+00]],
device='cuda:0', dtype=oneflow.float32)
x.to_local()
tensor([[-0.4363, 0.9985, -2.5387, 0.3003, 0.3803],
[ 0.0556, -0.8077, 1.1191, -2.1278, 0.1468]], device='cuda:1',
dtype=oneflow.float32)
由 local tensor 转换得到 global tensor¶
可以先创建 local tensor,再利用 Tensor.to_global 方法,将 local tensor 转为 global tensor。
下面的例子中,在2台设备上分别创建了 shape=(2,5) 的2个 local tensor。
注意经过 to_global 方法后,得到的 global tensor 的 shape 为 (4,5)。
这是因为选择的 sbp=flow.sbp.split(0),2个形状为 (2,5) 的 local tensor,需要在第0维拼接,得到 (4,5) 的 global tensor。
import oneflow as flow
x = flow.randn(2,5)
placement = flow.placement("cuda", [0,1])
sbp = flow.sbp.split(0)
x_global = x.to_global(placement=placement, sbp=sbp)
x_global.shape
import oneflow as flow
x = flow.randn(2,5)
placement = flow.placement("cuda", [0,1])
sbp = flow.sbp.split(0)
x_global = x.to_global(placement=placement, sbp=sbp)
x_global.shape
实践 SBP Signature 的作用¶
数据并行¶
以下的代码对应了 常见的分布式策略 的数据并行。
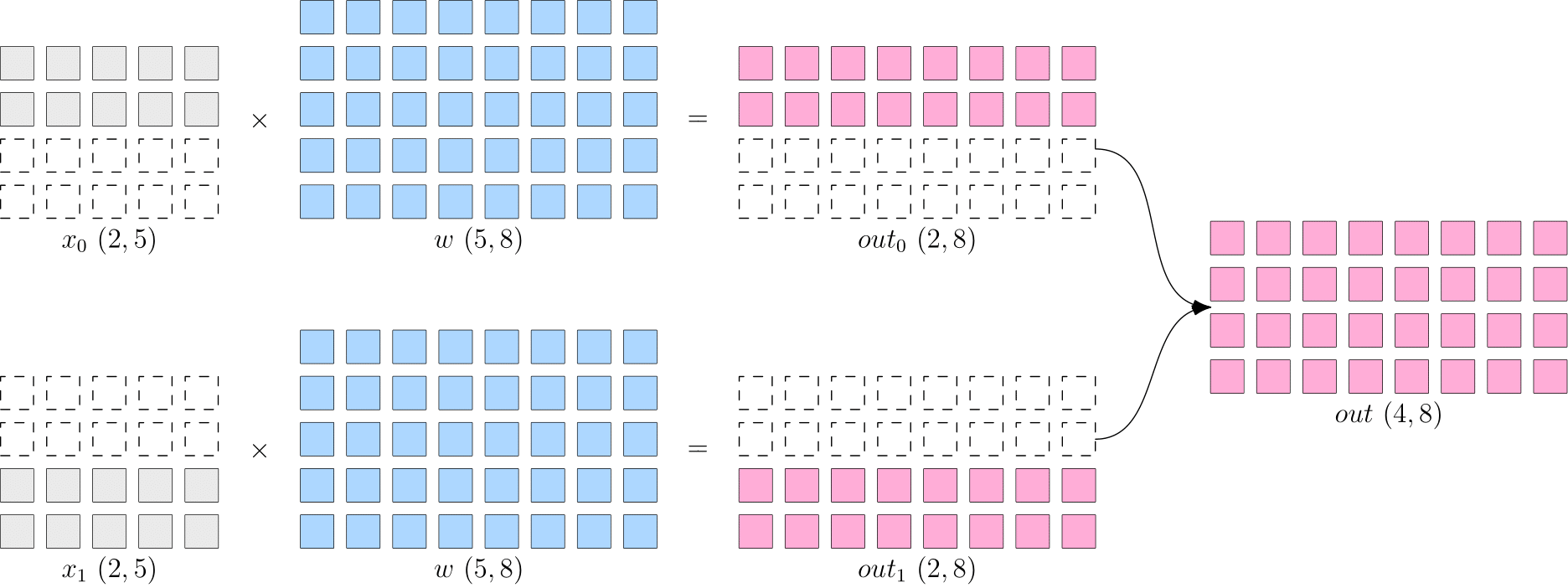
import oneflow as flow
placement = flow.placement("cuda", [0,1])
x = flow.randn(4,5,placement=placement, sbp=flow.sbp.split(0))
w = flow.randn(5,8,placement=placement, sbp=flow.sbp.broadcast)
y = flow.matmul(x,w)
y.sbp
y.shape
import oneflow as flow
placement = flow.placement("cuda", [0,1])
x = flow.randn(4,5,placement=placement, sbp=flow.sbp.split(0))
w = flow.randn(5,8,placement=placement, sbp=flow.sbp.broadcast)
y = flow.matmul(x,w)
y.sbp
y.shape
可以观察到,flow.matmul 根据输入 x 与 w 的 SBP 分别为 split(0)、broadcast。OneFlow 自动推导出输出 y 的 SBP 应该为 split(0),完成计算,得到 shape=(4,8) 的矩阵。输出:
(oneflow.sbp.split(dim=0),)
oneflow.Size([4, 8])
(oneflow.sbp.split(dim=0),)
oneflow.Size([4, 8])
模型并行¶
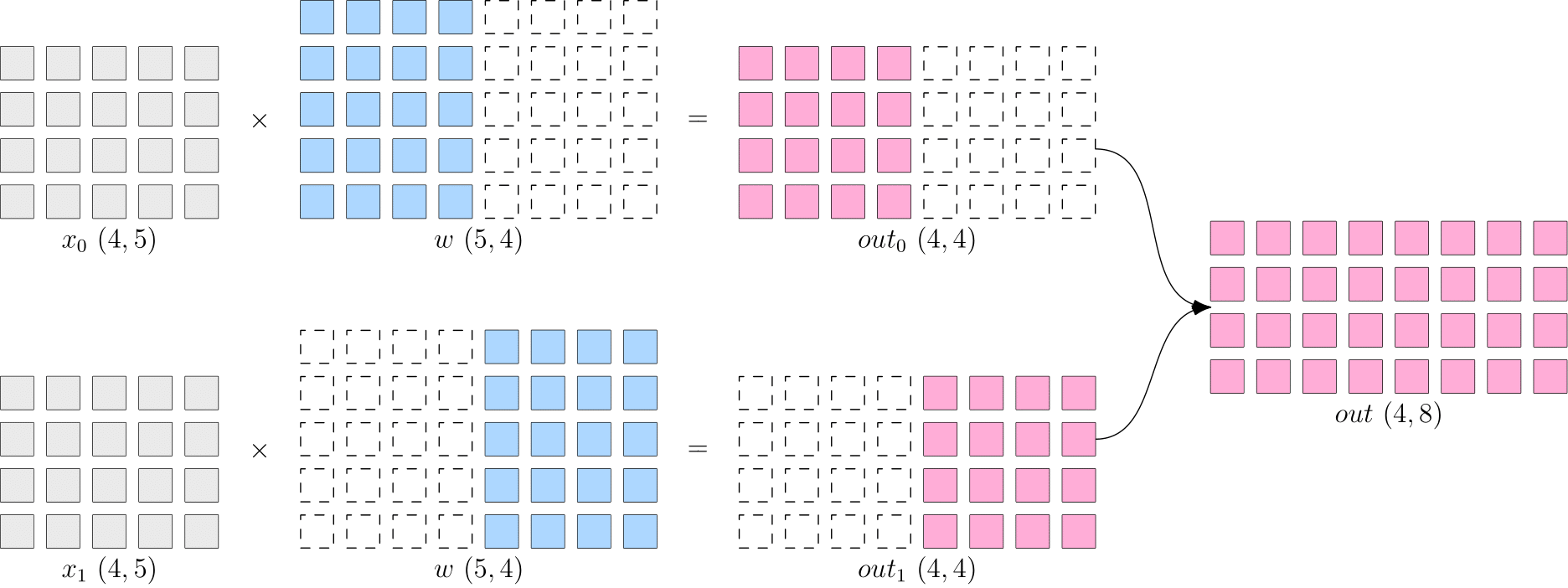
以下的代码对应了 常见的分布式策略 的模型并行。
import oneflow as flow
placement = flow.placement("cuda", [0,1])
x = flow.randn(4,5,placement=placement, sbp=flow.sbp.broadcast)
w = flow.randn(5,8,placement=placement, sbp=flow.sbp.split(1))
y = flow.matmul(x,w)
y.sbp
y.shape
import oneflow as flow
placement = flow.placement("cuda", [0,1])
x = flow.randn(4,5,placement=placement, sbp=flow.sbp.broadcast)
w = flow.randn(5,8,placement=placement, sbp=flow.sbp.split(1))
y = flow.matmul(x,w)
y.sbp
y.shape
可以观察到,flow.matmul 根据输入 x 与 w 的 SBP 分别为 broadcast、split(1)。OneFlow 自动推导出输出 y 的 SBP 应该为 split(1),完成计算,得到 shape=(4,8) 的矩阵。输出:
(oneflow.sbp.split(dim=1),)
oneflow.Size([4, 8])
(oneflow.sbp.split(dim=1),)
oneflow.Size([4, 8])
扩展阅读¶
多机训练时的环境变量¶
本文的例子,通过设置环境变量配置分布式训练,仅仅是为了在交互式 Python 环境下方便查看实验效果。 如果不是学习、试验目的,而是生产需求,可以直接通过 oneflow.distributed.launch 启动分布式训练,该模块内部根据命令行参数自动设置了必要的环境变量。
MASTER_ADDR:多机训练的第0号机器的 IPMASTER_PORT:多机训练的第0号机器的监听端口,不与已经占用的端口冲突即可WORLD_SIZE:整个集群中计算设备的数目,因为目前还不支持各个机器上显卡数目不一致,因此WORLD_SIZE的数目实际上是 \(机器数目 \times 每台机器上的显卡数目\)。如我们这个例子中,是单机2卡的情况,因此WORLD_SIZE=2
RANK 和 LOCAL_RANK 都是对计算设备的编号,不同的是 RANK 是“全局视角”的编号,LOCAL_RANK 某个特定机器上的“局部视角”的编号。当是单机训练(单机单卡或单机多卡)时,两者是没有区别的。以上的例子中,有两个显卡,分别是0号和1号。
当是多机训练时,每台机器上的 LOCAL_RANK 的上限,就是每台机器上的计算设备的数目;RANK 的上限,就是所有机器上所有计算设备的总和,它们的编号均从0开始。(因为编号从0开始,所以不包含上限)
以两台机器、每台机器上有两张显卡为例,可以整理出每张显卡的 LOCAL_RANK 与 RANK 对应情况:
| RANK | LOCAL_RANK | |
|---|---|---|
| 机器0的第0张显卡 | 0 | 0 |
| 机器0的第1张显卡 | 1 | 1 |
| 机器1的第0张显卡 | 2 | 0 |
| 机器1的第1张显卡 | 3 | 1 |
Boxing(自动转换 SBP)¶
我们已经通过以上代码的例子,知道一个算子会根据输入 tensor 的 SBP 属性以及算子内置的 SBP Signature,自动设置输出 tensor 的 SBP。
但是,细心的用户可能会进一步思考,如果上游算子输出 tensor 的 SBP,与下游算子输入的需要不一致时,怎么办呢?
比如,假设在模型并行中,有2层矩阵乘法,在第一层和和第二层都做模型并行。
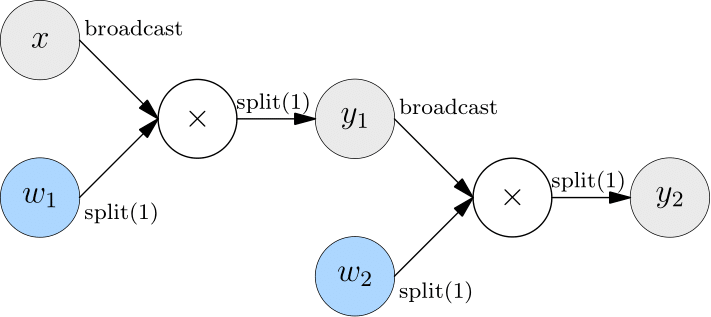
因为第一层的输出的 SBP(split(1)),并不是第二层输入所期待的(broadcast),这时候,OneFlow 会自动在上一层的输出和下一层的输出之间,插入 Boxing 操作,利用集合通信进行必要的数据转换。
从 split(1) 转换为 broadcast,相当于做了一次 AllGather 操作。如下图所示。
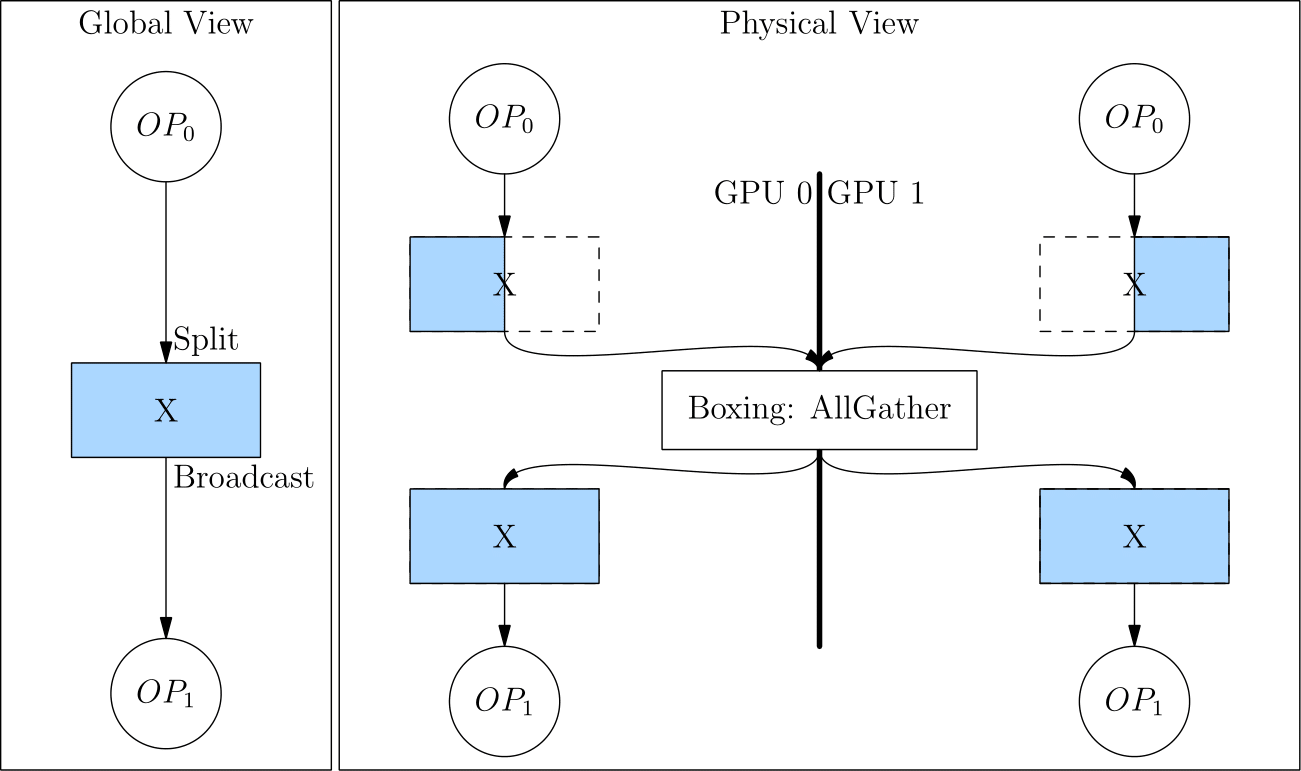
因为有 Boxing 机制的存在,使得用户只用关心少数关键地方(如 source 算子)的 SBP 设置,剩下的全部都可以交给 OneFlow 框架。